Proyecto full-stack en solitario · 2019–2020 · Angular · Firebase · ML
Makaw: previsión de finanzas personales
Una web en Angular + Firebase para gestionar las finanzas personales y prever los ahorros futuros, con un modelo Random Forest en Google Cloud que predice cuánto influye cada factor de tu vida en lo que ahorras.
Makaw es un proyecto de finanzas personales que desarrollé entre 2019 y 2020. Partió de una pregunta que casi todo el mundo se hace en algún momento: ¿cuánto podré ahorrar dentro de un año? Y si quiero ahorrar una cantidad concreta, ¿cuánto puedo permitirme gastar?
Las aplicaciones existentes resolvían solo la mitad. Las apps de los bancos y Fintonic son estupendas mostrando tu situación actual; Monefy lo es para registrar movimientos rápido a mano. Ninguna preveía el futuro, ni te daba un objetivo de ahorro concreto, ni dejaba a los usuarios hablar de finanzas entre ellos. Esos tres huecos son justo lo que Makaw quería cubrir, y, como ingeniero, lo interesante estaba en la arquitectura de debajo.
Qué puedes hacer en la app #s1
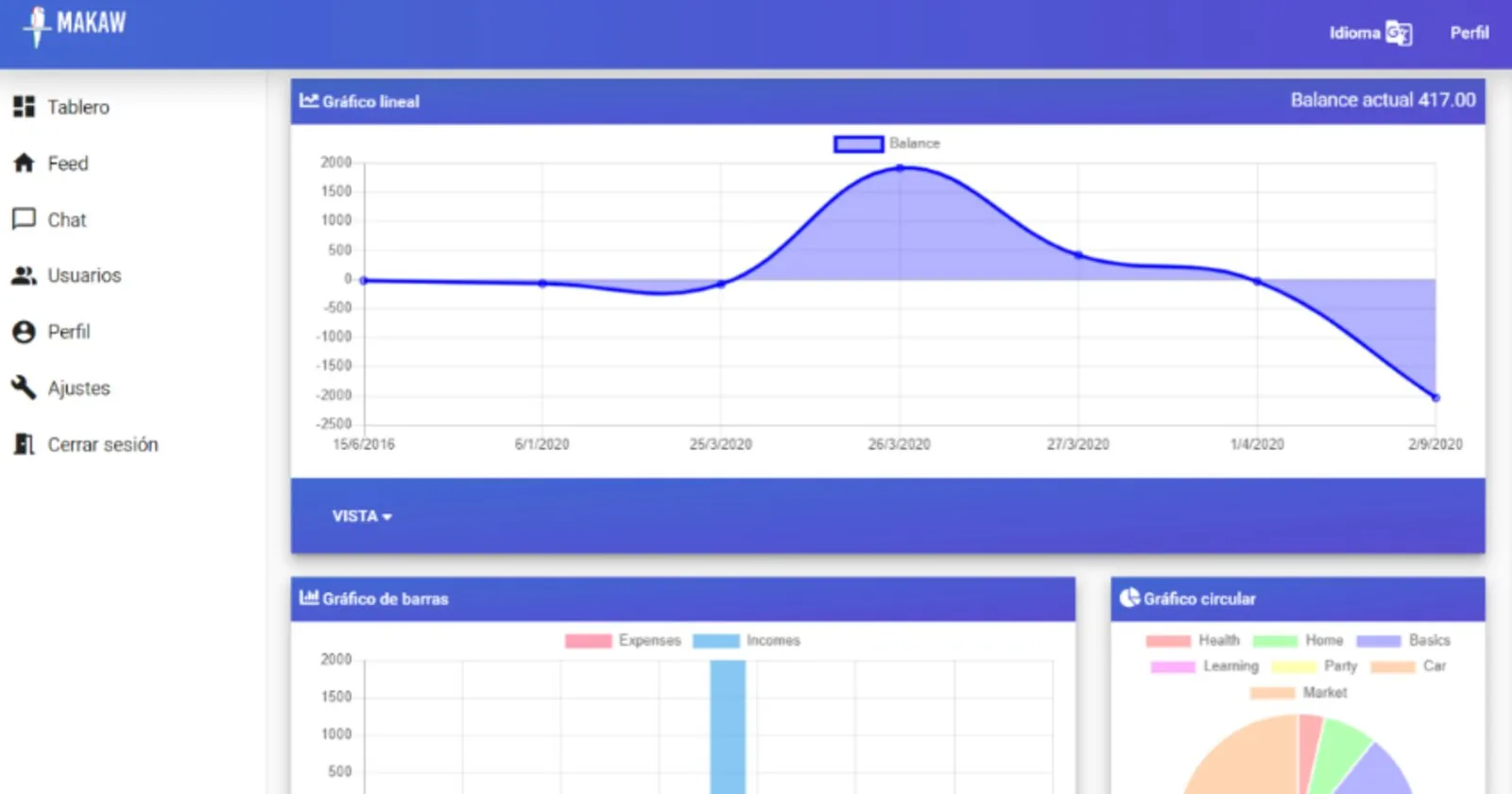
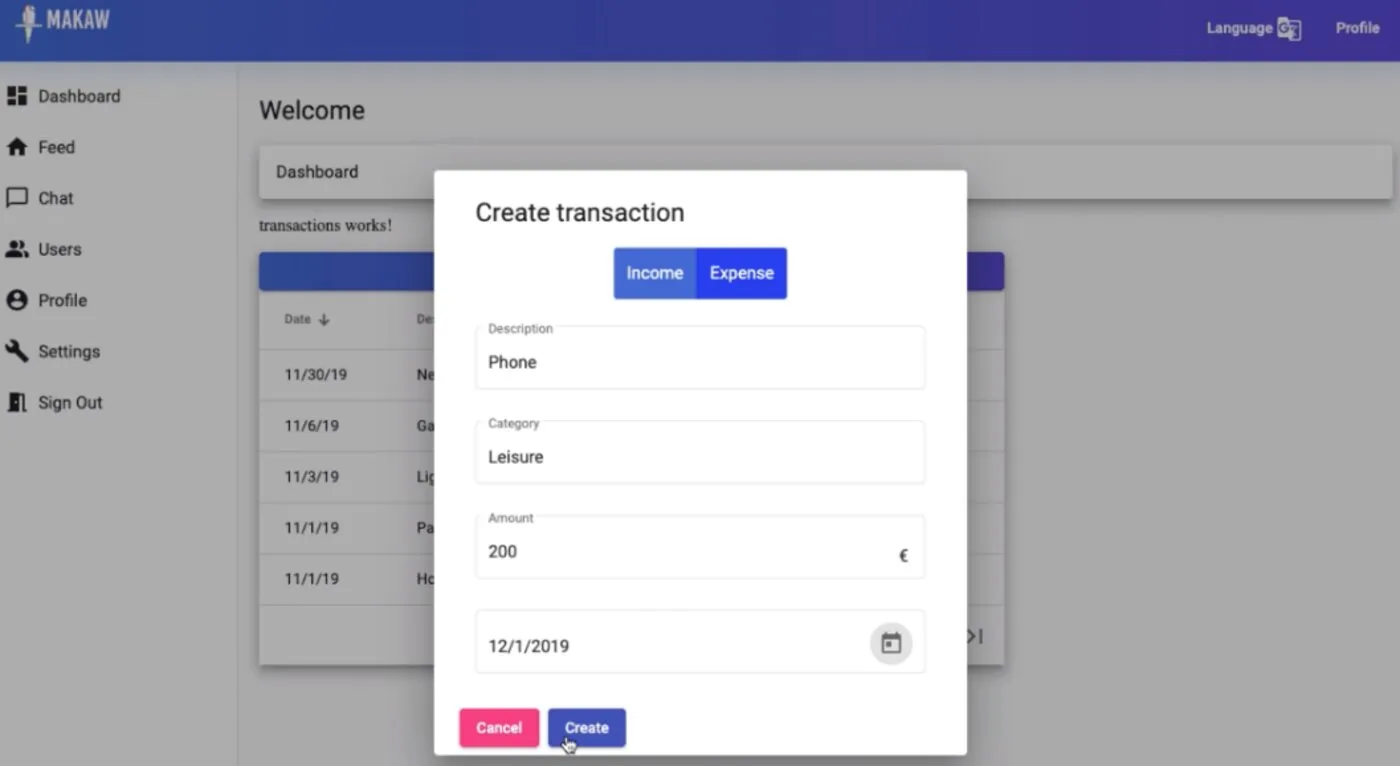
Empiezas registrando tus ingresos y gastos, incluidos los periódicos, como una nómina o una suscripción mensual. Donde la mayoría de apps se quedan en dibujar el pasado, Makaw proyecta esos movimientos periódicos hacia delante y traza la curva de a dónde va realmente tu saldo.
Alrededor de esa previsión se sitúan el resto de funcionalidades: una predicción con machine learning de cuánto suele ahorrar alguien con tu perfil, un cálculo de objetivos de ahorro que convierte «llegar a una cantidad para una fecha» en un gasto concreto por mes y por día, una puntuación financiera que te compara con gente como tú, y una pequeña capa social: un tablón estilo Twitter para consejos de finanzas personales y chat en tiempo real entre usuarios.
Está disponible en makaw-3a1bf.web.app y el código completo está en GitHub, ambos enlazados al final de esta página. Lo que sigue es la ingeniería de debajo, desde la infraestructura hasta el frontend.
Firebase como toda la infraestructura de backend #s2
En lugar de construir y mantener un backend tradicional, Makaw corre por completo sobre Firebase como Backend as a Service. Authentication gestiona el inicio de sesión (con proveedores OAuth disponibles de serie); Cloud Firestore, una base de datos NoSQL de documentos en tiempo real, es el corazón del sistema; las Cloud Functions alojan los endpoints serverless; Cloud Storage guarda el contenido generado por el usuario; y Firebase Hosting sirve la aplicación con despliegues de un solo comando y SSL.
La base de datos se modela como colecciones de documentos, no como tablas y filas. Usuarios, transacciones, chats y posts viven cada uno en su propia colección; un documento no es más que un conjunto de pares clave-valor (un objeto JSON), y el esquema puede variar de un documento a otro: justo la flexibilidad que da NoSQL cuando la forma de una entidad cambia con el tiempo.
De este mismo backend cuelga el pipeline de ML offline: una Cloud Function hace de puente entre la app de Angular y un modelo Random Forest servido en Google Cloud AI Platform, que detallo más abajo.
Chat en tiempo real y archivos de usuario en Firestore #s3
El chat es la funcionalidad donde más se nota el carácter en tiempo real de Firestore. Cada conversación es un único documento en una colección chats, y el id del documento se deriva de forma determinista: se toman los uids de los dos participantes, se ordenan alfabéticamente y se concatenan. Como la misma pareja produce siempre el mismo id, no hay tabla de búsqueda ni riesgo de dos conversaciones en paralelo: el id es la dirección.
Firestore devuelve entonces ese documento como un observable «infinito»: un array de mensajes que se reemite entero cada vez que alguien escribe, de modo que las pantallas de ambos participantes se actualizan en vivo sin hacer polling. La contrapartida de un stream sin fin es que desuscribirse pasa a ser responsabilidad tuya cuando se cierra la conversación.
Los archivos de usuario (imágenes de perfil y vídeo) viven en Cloud Storage, con subidas y descargas seguras gestionadas por Firebase. Los bytes pesados se quedan en Storage y dentro del documento de Firestore solo se escribe la referencia ligera (la URL de descarga), el reparto habitual que mantiene los documentos pequeños y las lecturas baratas.
Previsión de ahorros con machine learning #s4
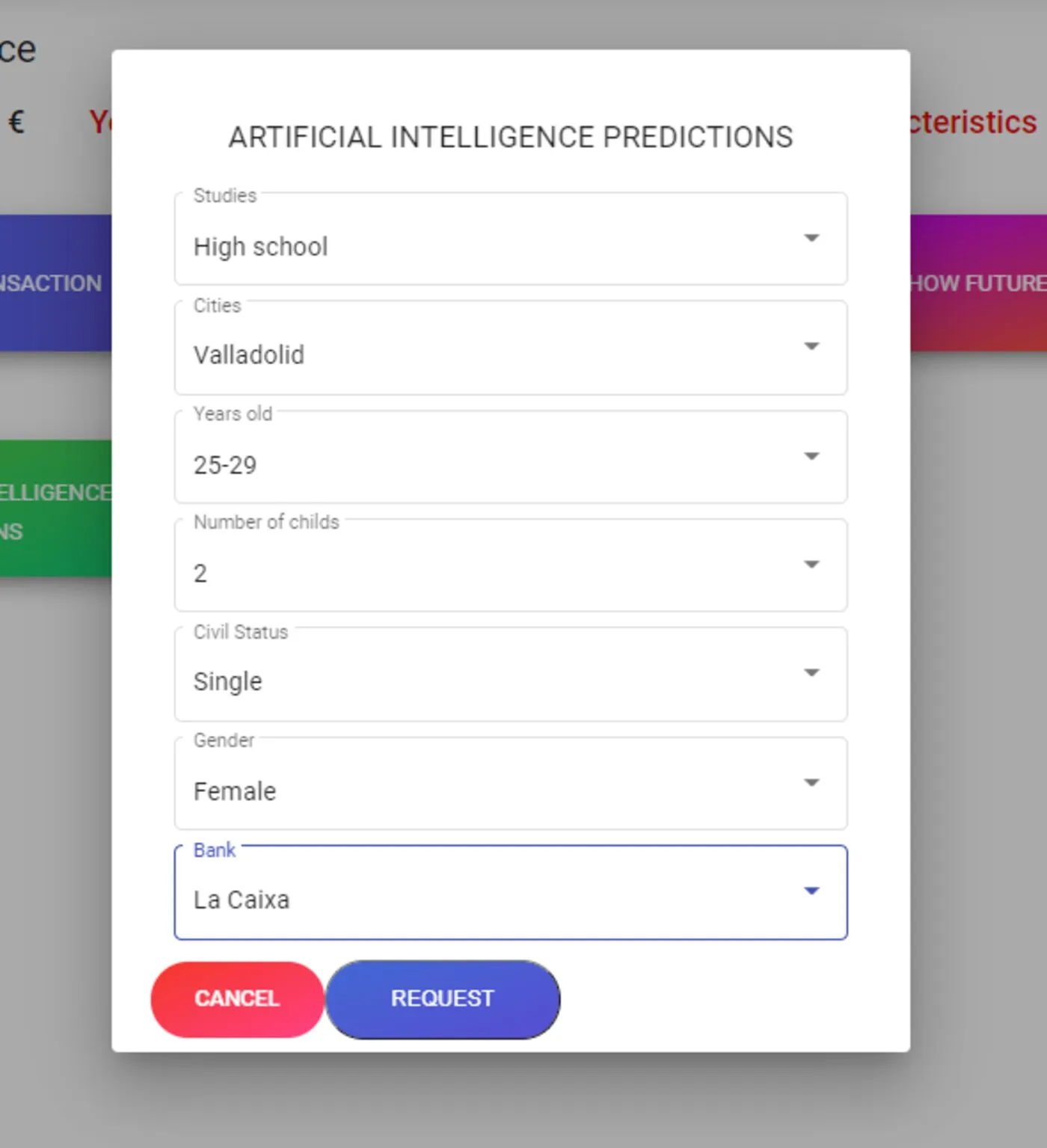
La funcionalidad estrella era la previsión. Prever a partir de datos históricos era la mitad fácil: proyectar las transacciones periódicas hacia delante y dibujar la curva del balance futuro. La mitad interesante era la US0009: predecir el ahorro a partir del perfil del usuario con un modelo.
Entrené un Random Forest para regresión (scikit-learn) en un notebook de Google Cloud Datalab, con todo el pipeline guardado en el directorio machine-learning del repo. Los árboles de decisión por sí solos sobreajustan; un bosque de árboles (aquí 1.200 árboles, profundidad 5, cada uno viendo una porción distinta de los datos y promediando sus salidas) generaliza mucho mejor y, de regalo, informa de la importancia de cada variable. Como la plataforma apenas tenía usuarios reales, un pequeño data-generator en Java sintetizaba el dataset, con una clase por variable: estudios, ciudad, edad, hijos, estado civil, género y un campo «entidad bancaria» deliberadamente aleatorio como control, para demostrar que el modelo encuentra la señal oculta dentro del ruido.
El resultado: un error absoluto medio de unos 135 € con el modelo frente a unos 518 € usando solo la media, es decir, unas 5 veces más preciso. Los pesos de las variables salieron así: ciudad de residencia 30 %, nivel de estudios 22 %, edad 19 %, género 15 %, hijos 12 %, y estado civil y entidad bancaria ~0 % (el control aleatorio pesó cero, como debía). El bosque entrenado se serializó a un forestmodel.joblib y se entregó a Google Cloud para servirlo.
Del notebook a producción: el puente serverless #s5
Sacar el modelo del notebook fue el verdadero reto de ingeniería, y el repositorio reparte ese trabajo en piezas separadas. El Random Forest entrenado se subió a Google Cloud y se publicó en AI Platform (ML Engine) como un modelo versionado llamado user_savings.
Una Cloud Function ligera de Firebase (predictSavings, desplegada en europe-west3 y alojada en el directorio firebase-functions) es el puente entre la app de Angular y ese modelo. Gestiona CORS (incluido el preflight OPTIONS), se autentica contra Google Cloud con una cuenta de servicio con scope cloud-platform, reenvía las instances de variables de la petición a ml.projects.predict mediante el cliente googleapis y devuelve la predicción. Casi todo el dolor aquí fue de autorización IAM, no del modelo en sí.
Un directorio aparte, cloud-functions, contiene un script experimental con el Admin SDK que dejé como andamiaje para una futura funcionalidad de servidor: su commit está marcado con sinceridad como «ignora esto, es solo un ejemplo para la próxima feature». La puntuación financiera, en cambio, se quedó en el cliente, en Angular, con solo un calculateScore esbozado y comentado para el día en que se moviera al backend.
Una arquitectura por capas alrededor del patrón fachada #s6
Antes de escribir funcionalidades dediqué una etapa inicial de «echar raíces» al diseño del que colgaría todo lo demás. La aplicación se divide en tres capas: una capa core (estado y acceso a la API), una capa de abstracción (las fachadas) y una capa de presentación (los componentes).
Cada dominio (transacciones, usuarios, chat) expone una fachada: un servicio inyectable que encapsula lo que los componentes pueden ver y hacer. Los componentes nunca tocan la API ni el estado directamente; solo hablan con la fachada. Esa única indirección es lo que mantuvo el código mantenible a medida que crecía.
Estado reactivo con RxJS y flujo unidireccional #s7
El estado vive tras la fachada como un BehaviourSubject: un array de transacciones que empieza vacío y se expone a los componentes solo como Observable. Un componente smart (el contenedor) pide a la fachada que cargue los datos, se suscribe a transactions$ y obtiene respuesta inmediata gracias al valor inicial; cuando más tarde responde la API, la fachada hace next(transactions) y la suscripción se actualiza.
A partir de ahí todo es estrictamente unidireccional: el componente smart pasa el observable hacia abajo a los componentes dumb (las gráficas lineal, de barras y circular) como @Input. Cada hijo se suscribe y deriva su propio observable interno, de modo que sus transformaciones nunca alteran el stream del padre. Los cambios fluyen hacia abajo, nunca hacia arriba; las ediciones vuelven a través de eventos @Output que piden a la fachada actualizar el estado. Esta misma forma se reutilizó tal cual para usuarios y chat.
Puntuación, objetivos de ahorro, tablón y chat #s8
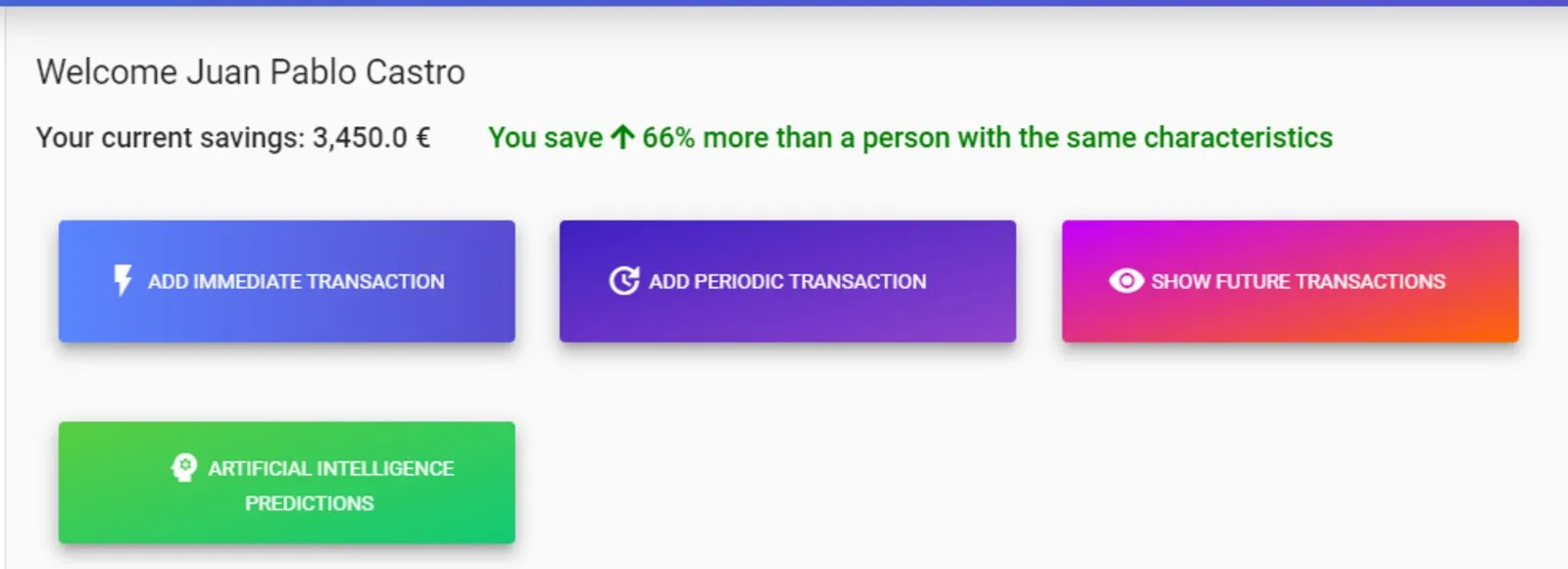
Sobre la previsión se asentaba la capa social y de objetivos. La puntuación financiera compara tus ahorros actuales con la media de los usuarios que comparten tu perfil (currentUserSavings / peopleAverageSavings): por debajo de uno se muestra en rojo con el porcentaje que te falta, por encima de uno en verde, y a partir de 2× cambia del porcentaje a un «X veces la media».
Los objetivos de ahorro te dejan elegir una fecha futura; la app calcula lo máximo que podrías ahorrar para entonces a partir de tus transacciones periódicas, con un slider (cableado con RxJS suscribiéndose a ambos inputs del formulario) que recalcula el gasto por mes y por día en vivo mientras lo arrastras.
El tablón es un muro estilo Twitter para consejos de finanzas personales: una colección posts donde cada post lleva subcolecciones anidadas de comments y likes, mantenidas en sincronía por los mismos observables en tiempo real de Firestore, asumiendo de buena gana la redundancia de datos que NoSQL cambia por lecturas más simples y rápidas. El chat, tratado más arriba, es la capa de mensajería en tiempo real entre usuarios.
Qué me llevo #s9
Makaw fue donde noté por primera vez la recompensa de invertir en arquitectura antes que en funcionalidades. La base de fachada más RxJS hizo que la gestión del estado fuera de verdad mantenible, y la separación entre componente y servicio hizo que la librería de cálculo de transacciones y la UI reutilizable (tabla, navbar, tarjetas) vinieran gratis en cada pantalla nueva.
También me enseñó a estimar sin experiencia previa, a documentar el trabajo según avanzaba (un rastro disciplinado de Trello y git), y que lo más difícil de poner ML en producción rara vez es el modelo: son los permisos y la fontanería que rodean su despliegue. Años después, trabajando con Angular profesionalmente, veo muchas cosas que refactorizaría hoy, lo cual tiene su propia satisfacción.